本文的知识来自于我的大学课程:数据可视化。在文中,我会分享自己的课程笔记与数据可视化项目的技术与实现方式。技术方面我主要会使用R语言,基于csv文件进行分析。我会使用到ggplot2等R语言的库。
当前的文章仍处于更新阶段。
Data Abstraction & Task Abstraction
- “What”(我们要可视化什么?)→ 数据本身如何结构化、属性类型如何分类。
- “Why”(我们为什么要可视化?)→ 我们希望通过可视化完成什么认知或分析任务。
Data Abstraction:What
- 数据类型不仅仅是表格(tabular),还有**网络(network)和空间(spatial)**数据:
- 表格数据:每行是数据项(item),每列是属性(attribute/dimension)。
- 网络数据:有节点(node)和连接(link),如社交网络,树(tree)是网络的一种特殊情况。
- 空间数据:有空间位置和几何形状(如地理边界、场数据),常见于地理和科学可视化。
- 属性类型决定如何分析与可视化:
- Categorical(类别型):如城市名,没有顺序,不能做加减。
- Ordinal(有序型):如T恤码(S/M/L),可排序,不能做加减。
- Quantitative(定量型):如数量、长度,有顺序且可算数运算。
- 特殊属性:如循环型(周期型)数据,diverging(有中心点的分布),sequential(单向有序)。
- 不同属性类型决定了适合的数据分析与可视化方式。例如,平均值只适合quantitative数据,排序适合ordinal。
⠀Task Abstraction: Why
- 数据可视化的目的是帮助人完成认知/分析任务,不是单纯做“漂亮的图”。
- 必须明确任务目标(即viewer想完成什么认知/分析),典型任务包括:
- 比较(Compare)
- 查找极值(Find extremum)
- 判断分布(Characterize distribution)
- 识别异常(Identify outlier)
- 找相关性(Browse correlation)
- 发现趋势(Discover trends)
- 派生(Derive,例如计算balance)
- 推荐采用动词+目标的组合方式描述任务(如compare trends, identify outliers等)。
- 任务有抽象层级,从低级泛化(适用于所有领域)到高级领域特定(如“对比不同社区的稳定性”)。 ⠀“派生(Derive)”任务的重要例子
- 某些任务本可以直接派生数据(如进出口差额),不应让观众自己算,应直接在可视化中呈现派生结果(提升易用性)。
设计原则总结
- 设计可视化前,先明确数据类型和属性类型(what),再明确认知/分析目标(why),两者决定了合适的可视化方法。
- 好的可视化应让目标任务尽量直接、低认知负担地完成,而不是让观众“脑补”数据推导。
Marks & Channels
基础概念
- Marks(图形标记):可视化的基本几何元素,常见有点(point, 0维)、线(line, 1维)、面(area, 2维)。体积(3D)很少用。
- Channels(视觉通道/属性):Marks的外观属性,用来编码信息,包括位置(position)、颜色(color)、大小(size: 长、面积、体积)、形状(shape)、**方向(orientation)**等。
角色
- Marks 通常对应数据项(如一个点、条形等)。
- Channels 映射数据属性,是“编码(encode)”信息的手段。
- 常用动词有:对应(corresponds to)、关联(associated with)、代表(represents)、编码(encodes)、映射(mapped to)。 Channels 分类与数据匹配
- Identity Channels(辨识/分类通道):表达“是什么/属于哪类”,适合**类别(categorical)**数据。如颜色、形状。
- Magnitude Channels(数量/量感通道):表达“有多少/数值大小”,适合**有序(ordinal)或定量(quantitative)**数据。如位置、长度、亮度、面积等。
视觉编码的两大原则
- Expressiveness Principle(表达性原则):视觉编码要准确表达全部且仅表达数据固有的信息(如定类不能用有序通道)。
- Effectiveness Principle(有效性原则):重要的数据属性应用感知更敏锐的通道来表达,即“越重要的信息用越醒目的通道”。
Channels 的有效性排名(感知效果)
- 空间位置(Position):最准确,无论表达分类还是数量。
- 长度(Length)
- 角度/斜率(Angle/Slope)
- 面积(Area)
- 颜色亮度/饱和度(Color luminance/saturation)
- 颜色色相(Color hue)
- 形状(Shape)/纹理(Texture)
- 排名越靠下,区分和比较越困难。
感知心理学基础
- 人类对长度感知近似线性,对面积、亮度等感知存在压缩(非线性),即实际翻倍但感知未必翻倍。
- 视觉通道有效性有大量心理学实验支持(如Cleveland and McGill 1980s),空间位置一直都是最易被准确感知的。
设计指南与应用
- 重要属性优先用排名靠前的通道,如位置。
- 不要期望观众能准确区分排名较低通道的细微差异。 ⠀例子
- 三种产品利润随时间变化,利润(最重要)→用位置;
- 时间→用另一维度的位置;
- 类别(产品种类)→用颜色等身份通道。
Discriminability(可分辨性)
指通道内可以被感知和区分的不同取值的能力(如颜色的种数,泡泡的大小数)。
- How many distinct values can be distinguished within a channel
不同通道的可分辨值数有限(如颜色一般别超12种,否则难区分)。
取值太多会造成信息拥挤、难以辨识。
可分辨性受哪些影响
- 通道本身的物理极限(如颜色 vs. 位置)
- cardinality(基数):有多少不同值需要编码。
- 空间排列(有序 vs. 混乱排列更难区分)。
- 图形标记的尺寸(过小难分辨)。
- 上下文(同一色系、大小的挨着更难区分)。
应对可分辨性过低的策略
- 用其他身份通道(如空间分组而不是颜色)。
- 合并/聚类部分类别(如把州合成大区)。
- 只显示关心的类别,过滤掉无关内容。
- 用“faceting”把不同类别拆成多个小图(small multiples)。
Visual Separability(视觉分离性)
- 指多个通道组合时,观众能否分别聚焦于某一个通道的属性。
- Separable channels(如位置+颜色):可以分开关注,不互相干扰。
- Integral channels(如高宽的组合):容易整体感知,难以单独聚焦。
分离性设计建议
- 若需要观众单独比较/分析每个属性→选分离性高的通道组合。
- 若希望观众整体感知多个属性的交互关系(如正方形/长条反映比例)→选integral channels。
总结要点
- Marks是几何元素,Channels是视觉编码属性。
- 视觉编码要根据数据属性类型,匹配合适的通道,并按重要性分配有效性高的通道。
- 注意通道的可分辨性和分离性,避免信息拥挤和混淆。
Lesson 6
Story & Narrative
- 故事 (Story): 指的是叙事中的所有事件,即事实和数据 。它是“什么”(What)—— 原始的数据点、人物、地点和行动。
- 叙事 (Narrative): 指的是**“讲述”**这些事件的方式 。它是“如何”(How)—— 作者如何组织、排序、调整节奏并塑造这些事件,以使其对观众清晰且引人入胜 。
- 传统的叙事指南(如文学、电影)不足以用于基于数据和可视化的叙事 。因此,本章提出了一套“叙事设计模式”(Narrative Design Patterns),以帮助创作者设计数据驱动的叙事 。
Narrative Design Patterns
- A narrative pattern is a low-level narrative device that serves a specific intent. A pattern can be used individually or in combination with others to give form to a story.
- 即:一个服务于特定意图的底层叙事设备
- 它们不是具体的实现方式或代码 。它们是更抽象的概念,与最终的媒介(如网页、视频、印刷品)解耦 。
18种模式的5大分类 (Figure 5.2)
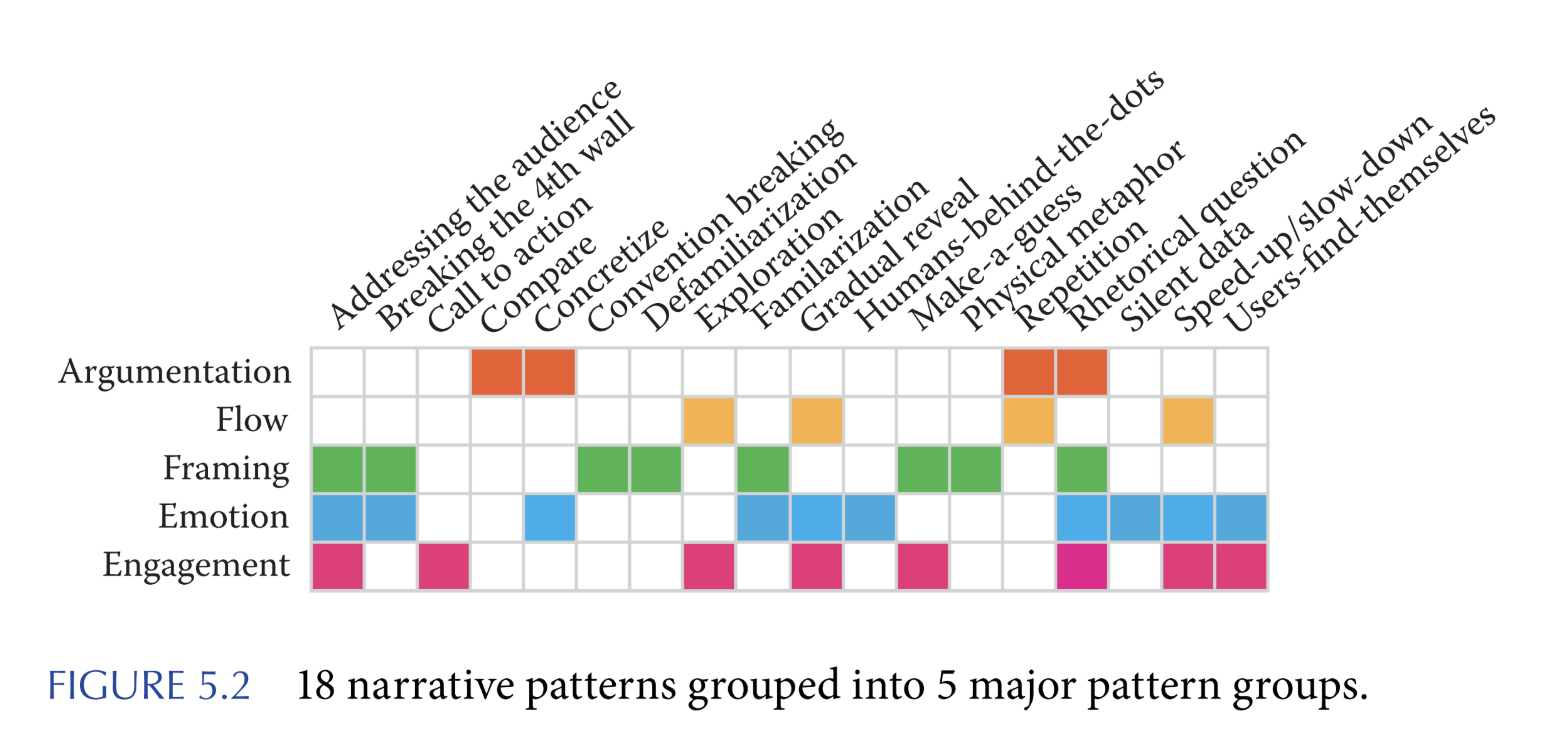
1. 论证 (Argumentation)
- 意图: 说服和使人信服 (persuading and convincing) 。
- 例子:
- Compare (对比): 并排呈现两个或多个数据集或可视化 。
- Concretize (具体化): 用具体的视觉对象(如ISOTYPE中的小人图标)来代表抽象的数据点或聚合统计数据 。
- Repetition (重复): 多次重新呈现一个现象,以加强叙事节奏或强调变化与差异 。
2. 流程 (Flow)
- 意图: 构建信息和论点的序列、节奏和步伐 (structuring the sequencing, rhythm, and pace) 。
- 例子:
- Gradual Reveal (逐步揭示): 逐渐地揭示数据元素,最终引向全貌和最终论点 。
- Speed-up/Slow-down (加速/减速): 改变叙事节奏。减速可以给观众时间思考 ;加速可以产生信息冲击的压倒性效果 。
3. 框架 (Framing)
- 意图: 决定事实和事件被如何感知和理解;利用或打破观众的预期 (how facts are perceived and understood; playing with expectations) 。
- 例子:
- Familiarization (熟悉化): 创建一个观众可以认同的熟悉入口点(例如,OECD的Regional Well-Being网站让用户先看自己所在的地区) 。
- Make-a-guess (让受众猜测): 邀请观众猜测数据或结果(例如,纽约时报的 “You Draw it Yourself”) 。
- Defamiliarization (陌生化): 以意想不到的方式呈现熟悉的事物(例如,将地图上下颠倒) 。
- Silent Data (静默数据): 故意隐藏数据,如同音乐中的休止符,让观众推断缺失的信息 。
4. 共情与情感 (Empathy and Emotion)
- 意图: 增强理解,重新定位读者的视角,或激发行动 (enhance understanding, provoke a call-for-action) 。
- 例子:
- Breaking-the-fourth-wall (打破第四堵墙): 叙述者直接与观众对话,打破舞台与观众之间的“墙” 。
- Humans-behind-the-dots (数据点背后的人): 通过“detail-on-demand”(如点击)来展示数据点所代表的个人故事(姓名、照片、经历) 。
5. 参与 (Engagement)
- 意图: 让观众感觉自己是故事的一部分,或能够控制与内容的互动 (feeling of being part of the story, or being in control) 。
- 例子:
- Rhetorical Question (反问): 直接向观众提问(例如 “What if I told you…")以引发思考 。
- Call-to-action (号召行动): 在叙事最后明确呼吁观众采取具体行动 。
- Exploration (探索): 通常在线性叙事结束时,允许用户自由互动和探索数据 。
关键讨论点
- 使用方式: 这些模式可以用于生成 (Generative)(帮助构思和创作新故事) 和分析 (Analytical)(帮助解构和批评现有故事) 。
- 三个时间概念: 作者区分了三种时间:
- Authoring-time (创作时间): 故事和叙事被创作出来的时间 。
- Presentation-time (呈现时间): 故事被呈现或被观众消费的时间 。
- Data-time (数据时间):** 数据本身所代表的时间 。
- 受众 (Audience): 模式的选择高度依赖于目标受众(背景知识、文化、互动意愿等) 。
L6: Exploration vs. Explanation
| 特征 | 探索 (Exploration) | 解释 (Explanation) |
|---|---|---|
| 中心 | 以数据为中心 (Data centered) | 以人为中心 (Human centered) |
| 理念 | 越多越好 (More is more) | 少即是多 (Less is more) |
| 受众 | 专家 (Experts) | 非专家 (Non-experts) |
| 产出 | 洞察 (Insights) | 信息 (Messages) |
| 环境 | 实验室设置 (Lab Setting) | 真实世界 (In-the-wild) |
| 风格 | 冗长、模糊 (Lengthy, Fuzzy) | 直截了当、精确 (To-the-point, Precise) |
- “数据驱动”下的故事 (Story) vs. 叙事 (Narrative) 这部分重申并扩展了我们从论文中得到的定义:
- 数据驱动的故事 (Story): 事实、洞察、信息 。它还包括背后的过程 (Processes),如数据转换 (transformation)、选择 (selection) 和聚合 (aggregation) 。
- 数据驱动的叙事 (Narrative):
- 提供上下文(例如人物、重要性、问题) 。
- 解释可视化本身 。
- 与观众对话 。
- 传达“核心信息” (Take home message) 。
经典故事结构 (Story Structure)
课件提出了一个经典的三段式戏剧结构 ,以及每个阶段的目标:
- 开头 (Beginning): 介绍、背景、问题 。
- 观众反应: 好奇 (Curiosity) 。
- 中间 (Middle): 事件、事实、关系、惊喜、发现、洞察 。
- 观众反应: 理解 (Understanding) 。
- 结尾 (End): 结论、解决方案、核心信息 。
- 观众反应: 行动 (Action) (例如“号召行动” Call-to-action) 。
课件 Part 2 (L6-storrytelling-Part2.pdf)
这部分深入探讨了实现叙事的具体结构、模式和体裁。
- 叙事结构的光谱 (Narrative Structures Spectrum)
课件(引用 Segel & Heer 的研究 )提出了一个从“作者驱动”到“读者驱动”的光谱:
- 作者驱动 (Author-driven):
- 强信息性 (Heavy messaging) 。
- 无交互性 (No interactivity) 。
- 线性 (Linear) 。
- 例子: 传统的报告或数据视频。
- 读者驱动 (Reader-driven):
- 无特定信息 (No messaging) 。
- 自由交互性 (Free interactivity) 。
- 例子: 探索性的可视化工具。
⠀2. 三种混合叙事结构 (Hybrid Structures) 大多数数据故事都处于上述两极之间,课件重点介绍了三种混合结构 :
- 马提尼杯结构 (Martini-glass Structure): 先引导(作者驱动),后探索(读者驱动) 。
- 交互式幻灯片 (Interactive Slideshow): 有一个整体的叙事结构(作者驱动),但允许在每一步进行局部探索(读者驱动) 。
- 例子: 课件中展示的“气候变化计算器” (Climate Change Calculator) 。
- 下钻式故事 (Drill-down Story): 很大程度上由读者驱动,读者可以选择自己感兴趣的部分深入探索 。
叙事模式 (Narrative Patterns)
引用了我们看的第一篇PDF(Bach et al. 的论文) 。它将“模式”视为实现叙事意图的工具。
- 课件中给出的例子包括:
- Contrast (对比)
- Concretize (具体化),特别是使用 ISOTYPE
- Scales (尺度),作为一种具体化的方式,使用参照物 (Reference) 和类比 (Analogies) 来帮助理解复杂的度量 (例如用 $100 美元钞票的体积来展示1万亿美元 )。
- Repetition (重复)
- Juxtaposition (并列)
- Incorporating the audience (融入观众)
七种叙事体裁 (Storytelling Genres)
最后,课件(再次引用 Segel & Heer )介绍了七种常见的数据叙事“体裁”或格式:
- 杂志风格 (Magazine Style)
- 带注释的图表 (Annotated Chart)
- 分区海报 (Partitioned Poster) 也称为信息图 Infographic
- 流程图 (Flow Chart)
- 连环画 (Comic Strip)
- 幻灯片 (Slide Show)
- 电影/视频/动画 (Film/Video/Animation) 课件还特别强调了 数据视频 (Data Videos) (如 “Inequality in America” )、现场演示 (Life Presentations) (如 Hans Rosling )和新兴的 数据漫画 (Data Comics) 作为重要的体裁。
总结
这三个文件(1篇论文 + 2份课件)共同为我们提供了STA313关于数据叙事的完整框架。
- Why (为什么):** Exploration vs. Explanation (课件 1)
- What (是什么):** Story (数据) vs. Narrative (讲述) (课件 1 & 论文)
- How (如何做):
- 高层结构 (Structure): Author-driven vs. Reader-driven 以及三种混合模式
- 底层工具 (Pattern): 18种模式,分为5组(论证、流程、框架、共情、参与)
- 最终形态 (Genre): 七种体裁(杂志、视频、漫画等)
Lesson 7
Design for Information by Isabel Meirelles 深入探讨了专题地图 (thematic maps) 的设计原理和方法。
1. 核心定义:专题地图 (Thematic Maps)
- 定义:专题地图是在一个基础地图 (base map) 上,呈现属性数据(定量的和定性的)的制图 。
- 目的:其主要目的不是地理导航,而是展示一个特定的“主题” ,例如社会、政治、经济或文化现象,以揭示这些现象在地理空间上的模式 (patterns) 和频率 (frequencies) 。
2. 简史 (Brief History)
- 专题地图可以追溯到17世纪下半叶
- 第一个专题地图:** 英国人 Edmond Halley 在1701年绘制的,显示磁场变化的等值线图 (isoline map)
- 第一个现代统计地图:** 法国人 Charles Dupin 在1826年绘制的,显示法国受教育程度的分级统计图 (choropleth map)
- “黄金时代”: 19世纪中叶(mid-1800s)是图形方法创新的“黄金时代”,这主要由各国政府认识到数值信息在规划人口福利方面的重要性所推动
3. 地图设计的三个核心领域 (Map Design: 3 Basic Areas)
制作数据地图涉及三个基本决策:
- 投影 (projection)
- 比例尺 (scale)
- 符号化 (symbolization)
A. 投影 (Projection)
- 定义:将地球的3D曲面转换为2D平面的数学转换
- 核心问题:所有投影都会在角度、面积、形状、距离或方向上产生扭曲 (distortions)
- 关键权衡:投影不能同时既是“正形投影” (conformal, 保持角度/形状) 又是“等面积投影” (equivalent, 保持面积)。
- 例子:** 墨卡托投影 (Mercator) 是正形的,适合导航,但它严重夸大了高纬度地区的面积(例如,阿拉斯加看起来和巴西差不多大,但实际上巴西的面积是阿拉斯加的5倍)因此非常不适合用来比较陆地面积 。
- 原则:在需要比较区域密度的地图(如点分布图)上,使用等面积投影至关重要。
B. 比例尺 (Scale)
- 定义:** 地图的缩减程度,即地图上的距离与地球上相应距离的比率
- 概念区分:
- 大比例尺 (Large scale) (例如 1:10,000):显示小区域的更多细节(例如城市街道图)。
- 小比例尺 (Small scale)** (例如 1:100,000,000):显示大区域的更少细节(例如世界地图)
- 原则:** 比例尺越小,可用于视觉标记和细节的物理空间就越少 。基础地图的细节应与比例尺相匹配。
C. 符号化 (Symbolization)
定义: 也称为视觉编码 (visual encoding),是将待可视化的现象(数据集)与最合适的视觉表现形式(图形元素和视觉属性)相匹配的过程 [cite: 371, 372]。
4. 制图的数据考量 (Data Considerations)
- 数据类型:
- 标称型 (Nominal):** 类别数据,用于区分(例如政党)
- 有序型 (Ordinal):** 允许排序,但没有确切的量级(例如小、中、大)
- 定量型 (Quantitative): 可以测量的数值(例如人口)
- 数据分布:
- 离散型 (Discrete):** 由单个项目组成(例如地图上的城市)
- 连续型 (Continuous):** 数据在空间上连续存在(例如温度)im
- 数据模型 (Data Model):** 数据可以被概念化为从突变 (abrupt)到平滑 (smooth),以及从**离散 (discrete)到连续 (continuous)**的光谱。这个分类有助于选择正确的地图类型。
5. 视觉变量 (Visual Variables)
- 本章的系统建立在 Jacques Bertin 的理论之上。
- 该理论将基本图形元素(点、线、面) 与“视觉变量”相关联,以传达数据。
- 关键变量及其适用的数据类型
- 位置 (Location / X, Y):适用于所有数据类型
- 大小 (Size) / 价值 (Value, 即颜色的深浅):适用于定量型和有序型数据
- 颜色色相 (Color Hue) / 形状 (Shape): 适用于标称型 (类别) 数据
6. 六种主要制图方法 (Graphical Methods)
该章节重点介绍了六种主要的专题地图绘制方法
1. 点分布图 (Dot Distribution Maps)
使用“点” (point) 元素来揭示现象的空间分布 类型:“一对一”(一个点=一个事件,例如 Dr. John Snow 的霍乱地图 或“一对多”(一个点=一个聚合值,例如 1 个点代表 10,000 人
- 优缺点:非常适合展示相对密度和聚类 (clustering) 但不善于显示绝对数量
- 规则: 必须使用等面积投影
2. 等级符号图 (Graduated Symbol Maps)
- 方法:使用大小 (size) 这一视觉变量来按比例表示量值
关键特征: 符号的大小与数据值成正比,而与其所在的地理区域面积无关这避免了分级统计图(见下文)中大面积区域可能带来的误导
- 历史首创:Charles Minard 在1858年使用分级饼图来表示供应巴黎的肉类
- 常见错误:** 不能按“半径”或“直径”来缩放符号,必须按“面积” (area) 来缩放
3. 分级统计图 (Choropleth Maps)
- 最流行的技术之一
- 它使用面积符号(通常是行政单位,如州或县)来展示聚合数据
- 核心原则 (1):必须使用标准化数据(例如密度、比率、平均值),绝对不能使用原始的绝对数据(例如总人口、总收入)
- 核心原则 (2):应使用有序的视觉变量,如颜色价值 (value)(从浅到深)或饱和度 (saturation)不应使用无序的颜色色相 (hue)(例如彩虹色)
- 颜色方案 (Color Schemes) (Cynthia Brewer 理论):
- 顺序型 (Sequential):适用于从低到高的数据(例如人口密度)
- 发散型 (Diverging):强调两个极端和一个有意义的中点(例如选举中偏向民主党或共和党的程度)
- 定性型 (Qualitative): 适用于标称型/类别数据
4. 等值线图 (Isometric and Isopleth Maps)
方法: 通过等值线来表示连续的3D表面 Isometric (等距线): 值可以被引用到具体的“点”(例如温度、海拔) Isopleth (等值线): 值是根据“区域”计算得出的派生值,不能引用到单个点(例如人口密度)
5. 流线图 (Flow and Network Maps)
方法: 描绘线性现象,通常涉及点与点之间的运动 (movement) 和连接 (connection)(起点和终点
关键编码: 线的宽度 (Line width) 用于表示数量,颜色色相 (Color hue) 用于表示类别 代表人物: Charles Minard 是这一领域的先驱,他绘制了关于谷物运输和棉花进口的流线图
6. 示意地图 (Area and Distance Cartograms)
- 方法: 故意扭曲 (distort) 地理区域的形状,以便将另一个变量(如人口)编码到空间面积 (spatial area) 上
- 类型:
- 邻近示意地图 (Contiguous): 保持拓扑结构(即相邻的区域仍然相邻),例如 “Pulse of the Nation” 地图
- 非邻近示意地图 (Noncontiguous): 用非重叠的形状(如圆形)代替原始形状,例如 Dorling cartogram,或《纽约时报》的奥运奖牌图
Chapter 7: “空间结构:地图” (Spatial Structures: Maps) 课件的核心要点。
这份课件建立在我们之前讨论的 Design for Information 章节之上,并提供了一个更结构化的框架 (What, Why, How) 和对关键挑战(特别是地图投影和分级统计图)的深入探讨。
1. 核心框架:What, Why, How
课件首先提出了一个用于思考空间可视化的框架
- What (数据类型): 你在绘制什么样的数据?
- Locations (位置): 0维的点数据
- Trajectories (轨迹): 1维的线数据
- Areas (区域): 2维的面数据
- Why (任务): 你希望观众从数据中理解什么?
- 位置数据任务: 查看分布、密度、数值、距离或时间性
- 轨迹数据任务: 找到共同路径、查看数值、长度、方向性或时间性
- 区域数据任务: 进行比较、找到最大/最小值、识别地理趋势和异常值
2. 关键挑战 (1):地图投影 (Map Projections)
这是地图可视化中最根本的问题。
核心问题: 将3D的地球仪展平到2D的地图上,必然会产生扭曲 (distortion)。
基本权衡 (Trade-off): 任何投影都只能保留1-2个属性(如形状、面积、角度、距离),而不能保留所有属性
常见投影与它们的权衡:
- Mercator (墨卡托) 投影: 保留形状 (shape) 。这是它最大的问题来源:它严重扭曲了面积 (area),使高纬度地区(如格陵兰)看起来比赤道地区(如非洲)大得多,而实际上非洲的面积是格陵兰的数倍
- Hobo-Dyer 投影: 保留面积 (area) 。这使其适用于比较密度,但会扭曲形状。
- Ginzburgh IV / Goode Homolosine 投影: 妥协 (Compromise) 方案,试图在面积和形状扭曲之间找到平衡
对轨迹的影响: 在2D地图(如墨卡托投影)上,地球上两点间的最短路径(大圆航线)会显示为一条曲线
3. 关键挑战 (2):分级统计图 (Choropleth Maps)
课件特别指出了这是“最常见…也最有害”的地图类型
- 核心缺陷: 分级统计图使用地理区域的面积来着色,但这会产生严重的感知偏见。
- 它们过度强调 (Overemphasize) 地理面积大的区域(这些区域的人口/数据密度通常很低)。
- 它们隐藏 (Hide) 地理面积小的区域(这些区域的人口/数据密度通常很高)。
- 课件中的加拿大地图示例: 加拿大北部人口稀少,但在分级统计图上占据了主导视觉地位,而人口稠密的南部城市(如多伦多、温哥华)则几乎看不见
4. 分级统计图 (Choropleth) 的替代方案
为了解决上述问题,课件提出了几种替代方法:
- Dot Maps (点分布图): 用点来表示密度,更直观
- “Bar” Maps (柱状图地图): 在每个区域上放置一个柱状图(或等级符号)
- Cartograms (示意地图): 故意扭曲地理区域,使其面积与某个数据变量(如人口或议会席位)成正比
- Tile Grid Maps / Equal Area Glyphs (瓦片网格图): 这是最有效的替代方案之一。它用大小相等的形状(如正方形或六边形)代表每个地理单元(如省或州),从而消除了地理面积的偏见
- Glyphs (符号图): 在每个地理单元(或瓦片)上放置一个小图表(如饼图、箱线图、笑脸,即Chernoff Faces)来显示多维数据
5. 其他地图类型
- Point Data (点数据):
- Heatmaps (热力图) / Isopleth Maps (等值线图): 显示点数据的平滑密度
- Elevation Maps (高程图): 使用3D高度(而非颜色)来表示密度值。优点是能显示巨大的数值差异,缺点是可能有遮挡 (occlusion)
- Binning (分箱): 将点聚合到离散的网格中(如六边形)并对网格着色,这是热力图的一种替代方案
- Trajectories (轨迹 / 流线图):
- 编码方式: 轨迹(线)可以通过粗细 (Thickness) 编码数量,用纹理 (Texture) 或色相 (Hue) 编码类别,用时间步长 (Time steps) 编码速度
- Geo-Temporal Data (时空数据):
- Small Multiples (小型多图): 最常用的方法,即并排显示一系列地图,每个地图代表一个时间点(例如,按年显示)
- Space-Time Cube (时空立方体): 一种3D方法,其中 (X, Y) 轴是地理空间,(Z) 轴是时间
- Glyph Maps (符号图): 在每个地理区域上放置一个小型时序图(如折线图或面积图)
Chapter 8 - Multidimensional Data Visualization
本讲座系统地介绍了针对不同维度数据(从低维到高维)的可视化技术,重点讲解了设计原则、常用图表的适用场景以及在数据分析中需要警惕的统计陷阱。
低维数据
(Low-Dimensional Data, < 3维) 这一部分主要关注单个变量或两个变量之间的关系。
单变量数据 (Univariate Data)
- 常用图表类型:
- 条形码图 (Barcode Plot) 与 数据点图 (Data Plot)。
- 直方图 (Histogram) 与 密度图 (Density Plot)。
- 箱线图 (Box Plot) 与 小提琴图 (Violin Plot)。
- 核心警示:不要过度简化数据 (Do not dumb down your data)
- 拒绝“炸药图” (Dynamite Plots): 这种带误差线的条形图被强烈建议避免使用,因为它掩盖了数据的真实分布。
- Anscombe’s Quartet (安斯库姆四重奏): 这是一个经典的统计学案例,展示了四组统计特性(如均值、方差、相关系数)完全相同的数据集,其图形分布可能截然不同。这强调了必须通过可视化来看数据的全貌,而不仅仅是看统计摘要。
- Datasaurus Dozen: 即使箱线图看起来一样,原始数据的分布形状(甚至可能是一只恐龙)也可能完全不同,因此必须可视化原始数据分布。
⠀
双变量数据 (Bivariate Data)
A. 定量 x 定量 (Quantitative x Quantitative)
- 散点图 (Scatterplot): 最基础且强大的工具,用于展示两个变量间的关系。
- 观察重点: 聚类 (Clusters)、趋势 (Trends)、离群值 (Outliers) 和相关性 (Correlation)。
- Scagnostics (散点图诊断学): 基于 Leland Wilkinson 的 “Grammar of Graphics” 理论,用于描述散点图特征的一系列指标,帮助识别数据模式:
- 包括:离群 (Outlying)、偏斜 (Skewed)、结块 (Clumpy)、稀疏 (Sparse)、条纹 (Striated)、凸形 (Convex)、细长 (Skinny) 等。
- 辛普森悖论 (Simpson’s Paradox):
- 在分组数据中出现的趋势(例如负相关),当数据合并后可能会消失甚至反转(例如正相关)。
- 启示: 分析数据时要尝试拆分群组,不要被整体趋势误导,相关性不等于因果性。
- Mekko Chart (马赛克图变体):
- 适用于展示两个变量相乘得到第三个变量的情况(例如:人均 GDP $\times$ 人口 = 总GDP)。矩形的面积代表结果,宽度和高度代表两个因子。
⠀ B. 定量 x 有序/分类 (Quantitative x Ordered/Categorical)
- 热力图 (Heatmaps): 适合展示矩阵数据(如月份 x 年份),通过颜色深浅表示数值大小。
- 蜂群图 (Swarm Plots / Beeplots): 适用于一个分类变量 + 一个定量变量。比简单的条形图更能展示每个类别下的数据点分布密度,避免点重叠。
- Bertin Matrices (贝尔坦矩阵):
- 主要用于分类数据。通过重排矩阵的行和列来揭示分类数据之间的模式(例如不同国家的社会属性聚类)。
- 条形图的设计空间:
- 根据数据类型选择行 (Row) 或列 (Column) 布局。
- 变体包括:镜像条形图 (Mirror Bar)、分面条形图 (Small Multiples)、子弹图 (Bullet Chart/Benchmark Bar) 等。
⠀
高维数据
当维度增加时,在二维屏幕上展示数据变得更具挑战性。
3D 图表 (3D Plots)
- 可以使用 3D 散点图 或 3D 柱状图。
- 缺点: 虽然直观,但存在 遮挡 (Occlusion) 和 深度感知 (Depth perception) 问题,难以精确读取数据,通常效果不佳。
⠀
散点图矩阵 (Scatterplot Matrix / SPLOM)
- 原理: 将所有变量两两配对形成矩阵。
- 用法:
- 对角线: 通常显示该变量自身的单变量分布(直方图或密度图),因为自己对自己作图没有意义($Y=X$)。
- 非对角线: 显示两两变量间的散点图。
- 优点: 可扩展性强 (Scalable),提供概览,易于解读,能看到所有变量间的两两关系。
- 缺点: 随着维度增加,图表会变得非常小,难以阅读。
- 交互技术: Scatterdice 是一种通过交互式导航在不同维度间切换的技术,解决了维度过多时矩阵过大的问题。
⠀
平行坐标图 (Parallel Coordinates Plot, PCP)
- 原理: 每个维度是一个垂直轴,每个数据点表现为一条穿过所有轴的折线。
- 模式识别 (如何解读):
- 平行线: 表示正相关 (Positive Correlation)。
- 交叉线 (X形): 表示负相关 (Negative Correlation)。
- 收敛/束状线: 表示聚类或群组 (Clusters/Groups)。
- 常见陷阱 (Caveats/Pitfalls): 1 轴的顺序 (Axes order): 只有相邻的轴才能直观比较相关性。如果两个相关变量隔得很远,你看不出关系。轴的顺序对图表的可读性影响巨大。 2 轴的刻度 (Axis scales): 不同维度的单位和范围可能完全不同(如马力 vs 重量),容易产生误解。 3 截断轴 (Truncated axes): 轴可能不从 0 开始,导致微小的差异被视觉放大,容易误导视觉。
⠀
字形图 (Glyphs)
- 原理: 将单个数据点编码为一个小图形,图形的不同视觉变量(如形状、大小、颜色)代表不同的维度。
- 典型案例:
- Star Glyphs (星形图): 从中心向外辐射的轴代表不同变量。
- Chernoff Faces (切尔诺夫脸谱图): 用脸部特征(如嘴巴弯曲度、眼睛大小)代表数据维度。
- Flower Glyphs (花朵图): 例如 OECD Better Life Index,用花瓣的长度和宽度代表国家的不同幸福指标。
- Dear Data 项目: (Giorgia Lupi) 手绘的创意数据字形,展示了极其丰富的数据编码方式。
- 适用场景: 适合查看 个体 (Individual elements) 的整体特征,便于比较特定的对象(如比较两个城市的综合指标)。
- 缺点: 很难看出变量之间的全局相关性。
⠀
降维 (Dimensionality Reduction)
- 课件中提到降维是一类通过数学变换减少数据维度的方法,但本课程并未深入讲解具体的算法细节,重点在于可视化层面的处理。
总结:你应该注意什么?
- 警惕统计陷阱: 在分析数据时,时刻记住 Anscombe’s Quartet(不要只看均值)和 Simpson’s Paradox(注意子群组的反转趋势)。
- 根据维度选图表:
- 2维: 散点图是王道。
- 多维总览: 用散点图矩阵 (SPLOM)。
- 多维相关性分析: 用平行坐标图 (PCP),但要注意调整坐标轴顺序。
- 个体对比: 用字形图 (Glyphs)。
- 避免 3D:尽量不要在 2D 屏幕上使用 3D 柱状图或 3D 散点图,除非只是为了展示大致形态而非精确分析。
- 视觉编码原则: 虽然可以用颜色、形状、大小来增加维度,但不要过度叠加,否则会导致图表难以阅读(Clutter)。
Chapter 9- Hierarchical and Relational Structure
关系型数据:网络/图 Graphs & Networks
这部分处理的是节点 (Nodes) 和连线 (Edges/Links) 的关系。根据可视化编码的选择,主要分为两大类:使用连接通道 (Connection Channel) 的节点链接图,以及使用矩阵视图 (Matrix Views) 的邻接表示。
1. 基础概念与布局
- Node-Link Diagram (节点链接图):
- 定义: 最常见的网络图,使用点标记 (Point marks) 代表节点,线标记 (Line marks) 代表连接。
- 优势: 非常适合理解网络的拓扑结构 (Topology tasks),例如路径追踪 (Path tracing)、寻找最短路径、或查找相邻节点。
- 距离概念: 距离通常以“跳数 (Hops)”这一离散量来衡量,而非连续的平面距离。
- Force-Directed Layout (力导向布局):
- 原理: 模拟物理引力与斥力。节点之间相互排斥(像磁铁),而连线像弹簧一样将相互连接的节点拉近。
- 特点: 算法通常从随机位置开始迭代优化。这导致它是非确定性 (Nondeterministic) 的,即每次运行结果可能不同,难以利用空间记忆。
- 作用: 能够揭示聚类 (Clusters) 和离群点,且算法相对容易实现和理解。
- 局限性: 容易陷入局部最优。且对于节点数量超过几百个的图,布局会迅速变成杂乱的“毛球 (Hairball)”。
⠀ 2. 核心挑战:稠密网络 (Dense Networks)
当网络中的连线太多时,会形成“毛线球 (Hairball)”,导致无法阅读。一般来说,当连线数大概超过节点数的 4 倍时,力导向布局就会失效。讲师重点介绍了几种解决拥挤的技术:
- 多层级力导向布局 (Multilevel Force-Directed Placement, sfdp) —— 补充技术
- 原理: 构建一个派生的聚类层级结构 (Cluster hierarchy),先布局简化的粗粒度网络,再逐步细化。
- 作用: 提高了处理大规模网络的速度和质量,不仅能避免局部最优,还能在一定程度上展示数千个节点网络的聚类结构。
- 模体简化 (Motif Simplification):
- 原理: 识别网络中重复出现的子结构(如扇形、双向连接、全连接的派系),然后用简单的字形 (Glyph) 替换它们。
- 作用: 降低视觉复杂度,直接展示结构特征。
- 邻接矩阵 (Adjacency Matrices) —— 重点内容
- 原理: 将网络转换为派生表 (Derived table)。行是起点,列是终点,单元格的颜色或填充表示有连接。
- 优点:
- 彻底消除线条交叉 (Occlusion): 解决了节点链接图的遮挡问题。
- 高可扩展性 (Scalability): 即使是非常稠密的网络也能显示,单一视图可支持 1000 个节点和 100 万条边。
- 可预测性与稳定性: 所需屏幕空间是可预测的,且添加新节点不会剧烈改变整体布局。
- 节点查找: 在有序列表中查找特定节点(通过标签)比在散乱的力导向图中查找要快得多。
- 节点度数估算: 可以通过计算一行或一列中填充单元格的数量来快速估算节点的度 (Degree)。
- 缺点:
- 路径追踪困难: 很难进行拓扑结构分析 (Topology tasks),如追踪多跳路径 (A传给B,B传给C)。
- 不熟悉: 用户通常需要经过训练才能解读矩阵视图。
- 模式识别: 通过重排 (Reordering) 行和列,可以发现特定的视觉模式。
- Cliques (全连通子图): 在对角线上显示为填充的方块。
- Clusters (聚类): 显示为高度互联但在矩阵中聚集的区域。
- 对比结论: 稀疏网络用 Node-Link,稠密网络用 Matrix。
- 边捆绑 (Edge Bundling):
- 原理: 像把电线扎起来一样,把走向相同的连线捆在一起。
- 优点: 极大地减少视觉混乱,能清晰展示宏观结构(如整体流向)。
- 缺点: 引入了歧义 (Ambiguity)。一旦线进了“捆”,你就不知道它是从哪根出来的,不适合追踪单个连接。
⠀ 3. 特殊类型的网络
- 多元网络 (Multivariate Networks): 当节点有属性(如性别、部门)时,可以使用 Pivot Graphs。它将具有相同属性的节点聚合在一起,只显示组与组之间的连接,非常适合宏观分析。
- 地理网络 (Geographic Networks):
- 痛点: 严格按照地图位置排列节点通常会导致严重的连线遮挡。
- 策略: 抽象化地理信息。不要死守地图位置,可以扭曲地图(Cartograms)、把地图变成圆环(Chord Diagram)或抽象成方块,以便为连线腾出空间。
⠀
第二部分:层级数据(树 Trees)
这部分处理的是只有父子关系、没有循环的结构。可视化编码主要分为连接 (Connection) 和包含 (Containment) 两种通道。
1. 显式可视化 (Explicit Techniques / Connection)
- 特点: 使用线(连接标记)明确连接父节点和子节点。
- 典型图表:
- 传统树状图 (Node-Link Tree): 常用垂直或水平布局,利用空间位置展示深度。
- 径向节点链接图 (Radial Node-Link): 根在中心,深度编码为离中心的距离,连线通常是曲线。
- 系统发生树 (Phylogram/Dendrogram): 常用于生物学,分支的长度通常代表相似度(越短越相似)。
- 缺点: 空间利用率低,随着节点增多,叶子节点(最底层的节点)通常画得很小。
⠀ 2. 隐式可视化 (Implicit Techniques / Containment & Position)
- 特点: 不用线,而是用包含 (Containment)(嵌套)、重叠或相对位置来表示父子关系。
- 典型图表:
- 冰柱图 (Icicle Plots): 像挂着的冰柱,利用垂直位置和大小显示深度,水平位置显示兄弟关系。
- 矩形树图 (Treemaps) —— 重点内容
- 原理: 利用嵌套的矩形。父矩形包含子矩形,所有子节点的面积之和等于父节点。
- 优势: 空间利用率 100%。非常适合展示叶子节点的属性值(如文件大小、GDP),特别是发现极值/离群值。
- 劣势: 不适合展示拓扑结构或层级深度。
- 布局算法: 讲座对比了 Slice-and-Dice(容易产生细长条,难比较)和 Squarified(正方形化,更容易比较大小)。
- Voronoi Treemaps: 用更自然的细胞形状代替矩形,视觉效果好但算法复杂。
⠀ 3. 极坐标布局 (Polar Layouts)
- 问题解决: 传统的树图越往下空间越小。极坐标布局(圆形)越往外周长越长,因此能容纳更多的叶子节点。
- 典型图表: 旭日图 (Sunburst Chart)。本质上就是把冰柱图卷成圆形,或者是使用径向布局的填充法。
- 混合网络 (Compound Networks):
- GrouseFlocks: 结合了连接(显示网络结构)和包含(显示聚类层级)的混合视图。
Comparison Table
| Task / Attribute | Best Idiom (According to Transcript) | Why? / Constraint |
|---|---|---|
| Correlation (2 vars) | Scatterplot | Most accurate (position channel). |
| Correlation (Many vars) | Scatterplot Matrix (SPLOM) | Shows all pairwise. |
| Correlation (Specific Pair) | Parallel Coordinates (PCP) | ONLY IF axes are adjacent. |
| Distribution (1 var) | Histogram / Density Plot | AVOID Dynamite Plots. |
| Sparse Network | Node-Link Diagram | Intuitive for path following. |
| Dense Network | Adjacency Matrix | No occlusion; shows cliques. |
| Path Tracing | Node-Link Diagram | Hard in Matrices. |
| Tree Leaves (Size) | Treemap | Space-filling. |
| Tree Structure (Deep) | Sunburst (Polar) | More space on periphery. |
总结:你需要注意什么?
- 根据数据密度选图表:
- 网络很稀疏?用 Node-Link (适合拓扑任务)。
- 网络密得像毛球(连线数 > 4倍节点数)?用 Adjacency Matrix (适合概览和查找)。
- 网络很稀疏?用 Node-Link (适合拓扑任务)。
- 2 根据任务目标选图表:
- 要看路径(A怎么到E)?用 Node-Link。
- 要看聚类(谁和谁是一伙的)或估算节点度数?用 Matrix。
- 要看宏观流向?用 Edge Bundling。
- 要看路径(A怎么到E)?用 Node-Link。
- 3 树图的抉择:
- 如果你的树非常深且叶子节点不仅有层级还有数值大小(如硬盘文件占用),Treemap 是最佳选择。
- 如果叶子节点实在太多,导致外层太拥挤,考虑用 Sunburst (旭日图)。
- 如果你的树非常深且叶子节点不仅有层级还有数值大小(如硬盘文件占用),Treemap 是最佳选择。
- 4 资源推荐: treevis.net是专门收集树形数据可视化的库,想找灵感时非常有用。