2026年1月10日 - LMA 0.0.3 更新
这次的更新杂谈我拜托Gemini写了,给我代笔,我不写了。未来我再加点开发杂谈吧。我累了,最近事情太多。啊…真是,从Python换到别的语言还是得适应。要是还是有朋友装不上dmg,那我真得跟苹果掰扯一下了。现在的dmg经过了Apple的公证,系统应该只是会提示你这东西是网上下的,不会再拦你了。我拿我的信誉担保软件的安全,希望这次Gatekeeper能放过我。
然后,我只是换了架构,但另外两个文件midi_parser.py和sample_parser.py我没改,这是我的核心搜索逻辑,但他它们还是有点bug。我在搜B的时候他会把别的调的降调也给拉进搜索,这估计是当时我疏忽了,但我只能先拿这个B这个字符去代替那个降号,不然我怕没办法显示。先凑合用吧,未来我会想办法本地内置一个新符号然后把一串不可能被搞错的字符给map过去,让显示和搜索都变正常点吧。但这个我现在不搞了。
其它的未来再说。好累。
开发杂谈正文 by Gemini
[2026年1月更新] 架构重构、交保护费与 Git 惊魂
距离上次写下开发杂谈已经过去了一段时间。这段时间里,LMA 经历了一次几乎是“推倒重来”级别的底层重构。虽然表面上看着还是那个熟悉的黑色窗口,但“引擎盖”底下的东西,已经完全换了一套。
- 告别 JSON,拥抱 SQLite 在早期的版本里,为了图省事,我用 JSON 文件来存储索引数据。对于几百个采样来说,这没问题。但当我的采样库膨胀到几万个文件时,JSON 的读写速度简直让人绝望,每次启动和搜索都能感觉到明显的卡顿。
于是,在这次 v0.0.3 更新中,我做了一个违背“偷懒祖训”的决定:全线切换到 SQLite。
现在的 LMA 不再是一个简单的文本阅读器,而是内置了一个微型关系数据库。配合上 PyQt6 的多线程(QThread)扫描,现在的体验是:几万个文件的索引瞬间入库,搜索响应是毫秒级的,而且在扫描文件的同时,界面再也不会假死卡住。这才是现代软件该有的样子。
同时,顺手把 PyQt5 升级到了 PyQt6,并且移除了 PyGame 依赖,改用 PyQt 原生的 QtMultimedia 调用系统音频引擎。这意味着软件体积更小,兼容性更好,再也不用担心 PyGame 在某些系统上发神经了。
- 我终于向苹果交了“保护费” 还记得我在上一篇杂谈里吐槽 MacOS 的 Gatekeeper 吗?那个“文件已损坏,请移至垃圾桶”的提示,简直是独立开发者的噩梦。
为了解决这个问题,也为了让大家安装时不再需要去终端里敲 xattr -cr,我最终还是妥协了——我加入了 Apple Developer Program。
是的,我交了那 99 美元的“保护费”。现在的 LMA v0.0.3 拥有了正经的 Developer ID 签名。打包流程也从简单的 zip 变成了正规的 DMG 封装。现在,你可以像安装任何正版软件一样,把 LMA 优雅地拖进 Applications 文件夹,Gatekeeper 再也不会把你拒之门外。虽然钱包痛了一下,但这顺滑的安装体验,值了。
- Git 惊魂:被 .venv 支配的恐惧 在这次开发中,我还犯了一个极其经典的“新手错误”,值得记录下来博大家一笑。
在配置 Python 虚拟环境时,我大意地没有更新 .gitignore,导致 Git 把我本地几千个库文件(venv)全部当成代码上传到了 GitHub。当我试图删除它们时,又陷入了 Everything up-to-date 和 Merge Conflict 的死循环。
看着云端仓库里那臃肿的 .venv-stable 文件夹,我当时的血压和 CPU 温度一样高。好在最终通过 git rm -r –cached 这一“驱逐令”,把这些垃圾从索引中剔除,同时保留了本地环境,最后强制推送(Force Push)覆盖了云端的错误历史。
这也再次提醒我(和各位):在写第一行代码之前,先写好 .gitignore,这真的很重要。
- 未来 目前的 Python 版本(v0.0.3)已经非常稳定且好用。但正如我之前所说,Python 在 GUI 开发上始终有着性能上限。接下来的日子里,我会放缓这个版本的更新频率,将精力投入到学习 Swift / SwiftUI 中。
LMA 的最终形态,应该是一个纯原生的 MacOS 应用。但在那之前,希望这个“性能过剩”的 Python 版 LMA 能陪大家度过愉快的创作时光。
(注:本段更新内容由我的 AI Copilot —— Gemini 协助整理与润色,它见证了我修 Bug 时崩溃的全过程。)
2025年10月21日 - 第一次开发杂谈
在八月份的时候,我就有开发本地采样管理器的想法。当时写了雏形,但我一直觉得太过简陋。今天我整了个还算能用的版本,就直接开源在GitHub上了。编程语言使用Python。在项目页面,大家可以看到使用说明等。
LMA的下载请于此进行. Google Drive算是个比较方便的地方,虽然看起来非常不正式。由于我需要等待更多的朋友去测试软件并给予我反馈,所以在此之前就在Google Drive发布了。等LMA更加完善后,我再考虑于GitHub发布正式的Release吧。当然能看到这个网页的朋友应该都能访问Google Drive。我就不单独再创建百度网盘的下载链接了(不过软件本身欢迎各位在遵守相关法规的前提下随意分发和传播)。
提一嘴开发的初衷。包括我自己在内,很多制作人所拥有的采样比实际会去查看的要多很多,其中一个原因是很多主流DAW缺少足够直观的采样管理系统;在线采样库的检索方式普遍比DAW自带的好,但它们不仅要钱还也无法进行本地采样管理。至于现有的本地采样管理软件,它们要么有植入广告要么要价$99,就不点名了。自己开发也是想做一个趁手的工具。
管理器名字暂定LMA。当前版本支持拖拽文件操作和按loop/one-shot的检索方式,也支持输入关键词搜索。我尽可能的在不被发律师函的情况下让它和某在线采样库操作思路足够相似,让大家上手就能用。不过我也写了操作指南,在GitHub的项目页面就有。我测试的时候暂时没遇到bug,有的话也希望大家反馈给我,我去修。同时,下一个版本我会加入更多打tag的方式,并优化音频预览操作逻辑。
以下是软件的操作指南。
安装
Windows用户请直接打开应用程序。系统可能会提示软件存在安全隐患之类的,请无视并继续运行。
MacOS用户请在打开dmg文件后将其拖拽到你的Application文件夹后打开。此时系统一样会提示你文件来自未经验证的开发者。请打开系统设置 -> 安全与隐私,向下滑动后找到新出现的系统提示,选择“仍然打开”,输入管理员密码后就可以打开LMA了。当前的dmg文件里存在一些我测试用遗留下来的列表,所以打开的时候你可能会看到非空的界面。请直接选择文件夹就行。这个问题我会在后续修复。
主界面
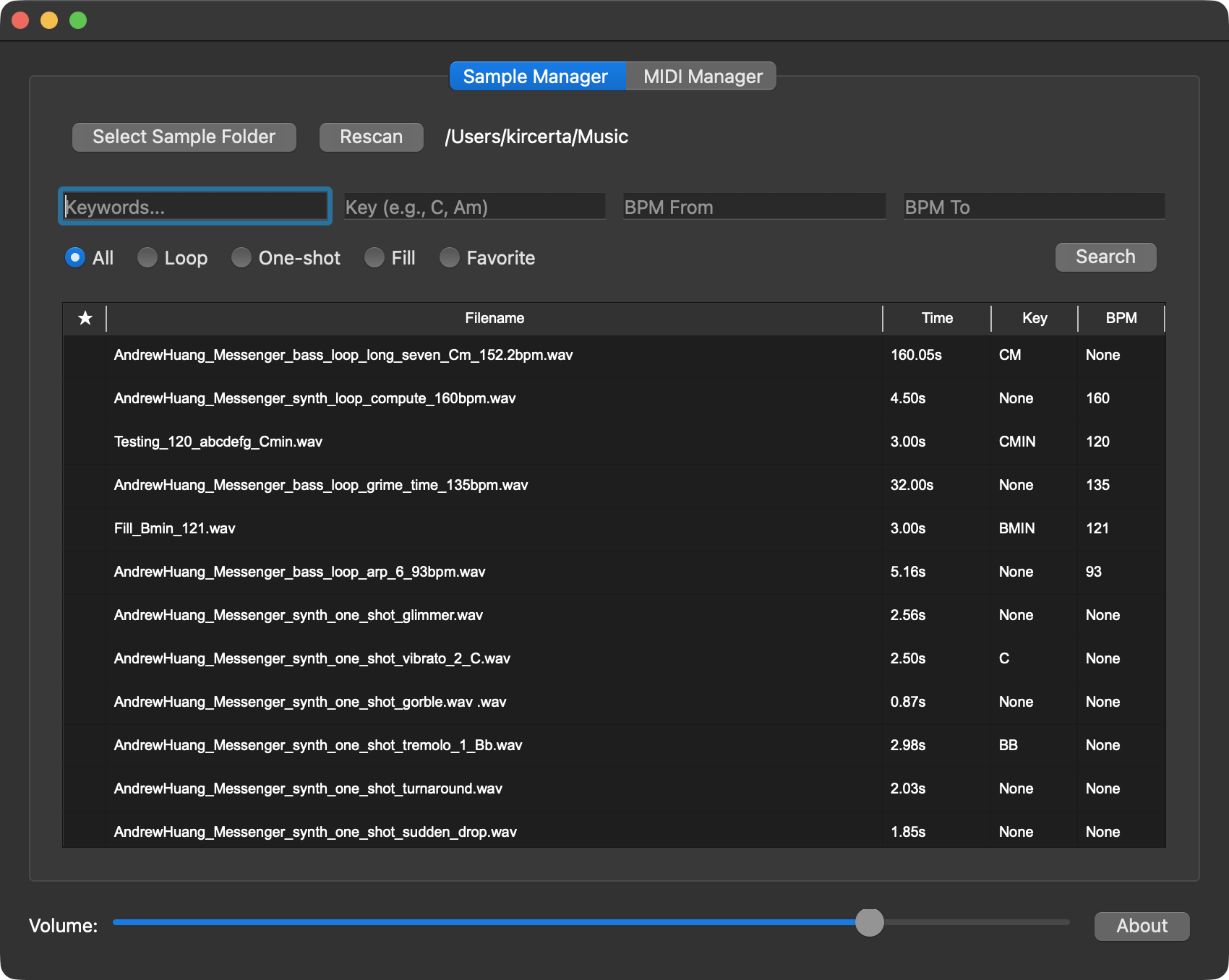
初始化
- 选择Select Folder,并选择你希望检索的本地采样的文件夹。
- 选择Rescan会重新扫描文件夹内的采样。
- 当采样数量较大时,LMA需要一段时间去分析和读取每一个采样的时长,并为它们创建索引。所以当你发现选择文件夹后LMA卡住,请等待一段时间,不要于中途强行关闭软件。
- 如果等待时间超过正常范围(如:10分钟)那么请考虑强制关闭


搜索采样与MIDI

- 在Enter Keywords处输入搜索关键词,点击search搜索采样。
- 点击下方窗口出现的采样进行音频预览,再次点击则可中断音频播放
- MIDI没有软件内预览功能,请拖拽到你的DAW进行预览。
- 选中采样/MIDI后即可拖拽采样至宿主软件/其它位置
- 拖拽后的采样会被复制到新的位置,如桌面或其它文件夹。
- 被拖拽的采样本身不会受到影响。
- 可以选择搜索loop或者one shot,在点击这些搜索条件后,一次搜索会被立即执行。
- 可以搜索指定范围BPM的采样
- 如果前后输入为同一个数字,则转而搜索精准BPM
- 可以搜索指定调性的文件。
- 敬请留意,由于LMA的搜索并非基于对音频文件的分析,只是基于文件的命名,因此部分命名有误的文件并不会被主动识别,需要使用者自行留意并手动修改命名格式。
- 由于调性命名的复杂性以及搜索逻辑本身的局限,使用者需暂时按照我设计的语法进行精准的采样搜索。
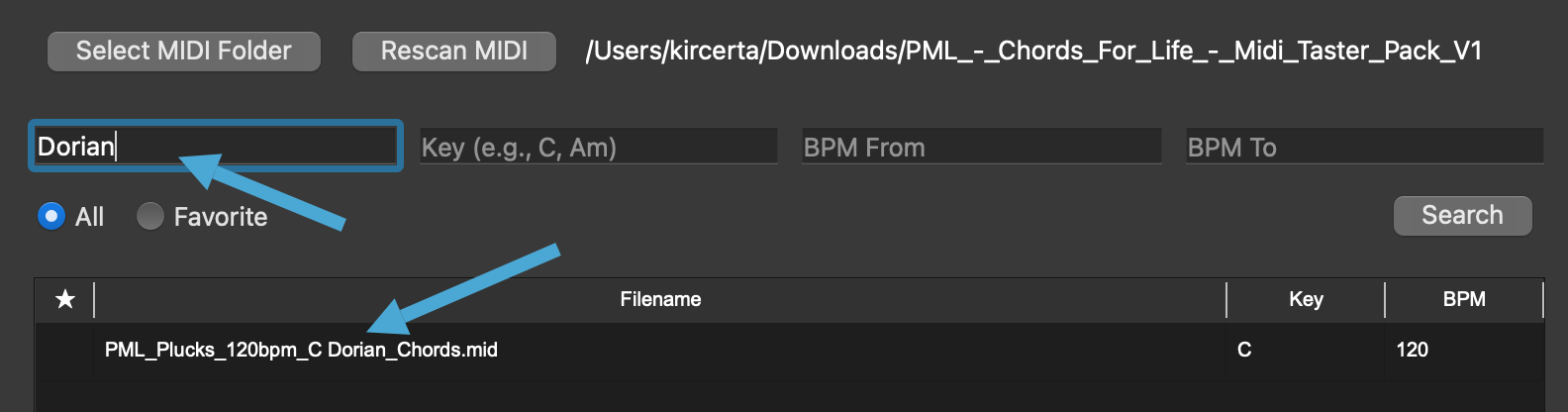
- 当你希望搜索大调时,请直接搜索目标音名(例如,A)。
- 此时,搜索的结果会包含大调,但也会包含其它内容。后续会解释。
- 当你希望搜索小调时,例如A小调,请按此格式:Am,进行搜索。
- 输入Amin/Aminor等都会导致搜索出现问题,这是因为我已经提前把同表达方式全部进行了标准化以确保结果指向正确目标。
- 其它类似Lydian,Dorian等调式的搜索可以在Keywords处进行,或者直接以大调的方式搜索,然后在结果中寻找。具体请看下面的例子。
- 当你希望搜索大调时,请直接搜索目标音名(例如,A)。
标记
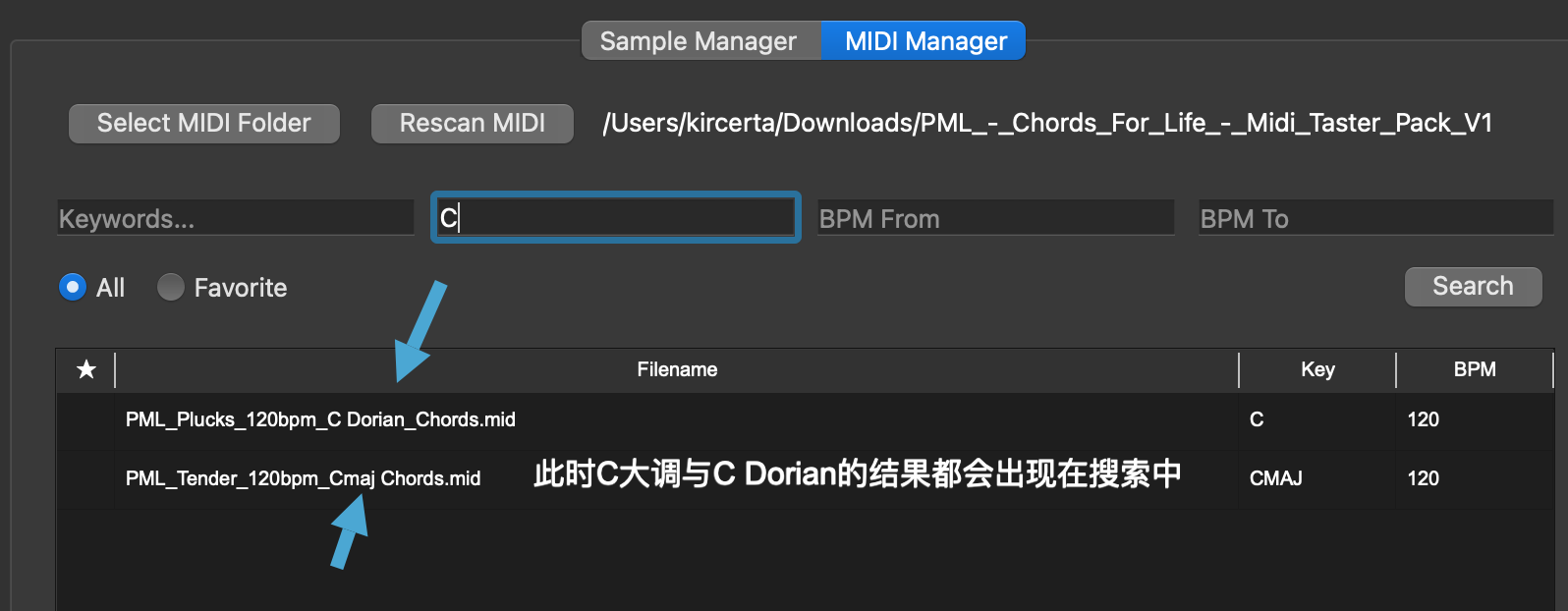
- 右键采样出现选项 “Add to collection”
- 选中后,列表中采样前会有星星标记。
- 标记采样并不会改变文件本身的名称,请放心。
杂项
- About 按钮会把你带到GitHub的项目页面
开发杂谈
高中的时候我所在的学校教授的是A-Level,其中我们需要选择3个自己感兴趣的学科进行学习,然后接受考试。我当时选择的是数学,物理和计算机科学。然而高中的时候我学习的计算机内容只是VisualBasic,一个基本被时代忘却的语言。但在那时我仍然建立了对数据结构的基本认识,对面向对象编程的印象,以及对IDE的了解等。虽然不深,但也算蹒跚学步的第一步。
大学后,我就读的专业是数学与统计学的融合专业(学校描述是 Mathematics and it’s Application in Statistics Specialist)。我大一的时候有进一步学习计算机科学的内容,有一门代号为CSC148的课程。也就是那时,我开始继续学习Python的语法,Python里的面向对象编程等。只是在之后,当我的方向彻底转向数学与统计,我就没有再特别多的接触过程序编写了。但我一直都对此感兴趣,也一直觉得如Tim Cook所说,编程能力应该是当下时代的一项基础教育,是必须被每一个人掌握的。
生成式人工智能的出现让编程的门槛变得前所未有的容易。开发LMA的过程中,Google的Gemini 2.5 Pro与OpenAI的ChatGPT 4.1都对我的效率产生了巨大的帮助。与此同时,一些很好用的类似soundfile的库也是得益于他们的介绍我才开始使用。
所以说,现在去学习程序设计,至少类似LMA这样实现难度并不大,只是各种知识都需要一些的软件而言,生成式人工智能完全可以领着你一步一步来做,去认识每一个function,去构建属于自己的搜索逻辑,去设计一个能用的GUI,诸如此类等等。要放在以前,你需要花费的学习成本和时间,是完全不同今日的。我也第一次自己尝试着为GitHub去贡献一些东西。
设计LMA的过程中,虽然知识和方向的引导都可以由生成式人工智能和你一起完成,但具体的排错与程序大方向的设计,仍然需要你自己去完成。比如,你希望一个软件做什么?你希望他的交互逻辑是什么样的?你希望这个按钮在哪,上面写什么,等等。这些如果全部都交给AI,那么它们大概率不会为你设计出你希望看到的软件。因为只有对自己的需求无比清晰,知道自己要设计的软件该以什么样的形式去实现什么样的功能,帮助解决什么样的问题,AI才能真正的起到他们该有的作用:成为你的copilot,为你的一举一动提供知识与建议。
还想再谈谈排错上遇到的一些问题。
首先文件检索逻辑上的问题。有一些采样的命名,实在是让我有些无语。但我也能理解业界的大家其实并没有一个统一的逻辑。所以这里只是简单用三个例子去说一下这样的问题该怎么解决:
- 文件1:abcdefg_02_Cmaj_120
- 文件2:hijklmn_BPM111_D_one_shot_119
- 文件3:opqrstu_A_Doriam_70bpm_loop
以上三个文件名字里忽略掉那些我瞎打的占位符,我们可以清晰地看到它们的特征:第一个是C大调名为abcdefg的一个东西,种类是loop还是one shot未知,文件名里有一个120大概率是指bpm120;文件2里,111这个数字前跟了很明确的BPM,D指向的是大调(因为没有出现Dm等特别指向小调的特征标识),是一个one shot,119可能代表着这个文件的编号;文件3里,你能发现这是个A Dorian的loop,BPM为70。那么这个时候当我想要尝试去搜索这些文件,我会遇到什么问题呢?
首先说一下我的文件名检索核心逻辑是把每一个分位符"_“分开的部分视作一个token。通过以下代码实现:
tokens = re.split(r"[_\s\-]+", name)
那么,假设我只是在每一个token里搜索我想要的信息,那么当我搜索bpm为111的采样时,文件2应该会出现在结果中。但如果我的文件tagging逻辑吧这里的119误认为是它的bpm,那会怎么办?是不是加一个“判定一个token指的是bpm必须要看是否数字前后跟了bpm三个英文字母”就可以解决这个问题了?好像可行。那么,文件1这里这个120我又要如何出处理?它是不是就不会被新的判定逻辑认为是BPM了?这里搜索BPM120的时候,它就不会出现在搜索结果中了?
要解决这个问题,分情况讨论则是最好的办法。程序并非人的大脑,其思维逻辑是绝对线性的。因此,人也要去假设自己只会用线性逻辑判断一个内容,然后寻找到一个不出错的解决方案。基于此,我给出的token判断逻辑是:
用正则表达式匹配一个完整的 token,看它是不是一个 2-3 位的数字(10-999),这个数字前后可能有 “bpm” 字样(不区分大小写)。如果匹配成功,并且 result[“bpm”] 还没被赋值,那么就取出这个数字(bpm_val)。
bpm_match = re.fullmatch(r"(?:bpm)?(\d{2,3})(?:bpm)?", token, re.IGNORECASE)
if bpm_match and result["bpm"] is None:
bpm_val = int(bpm_match.group(1))
接下来进行分类讨论:
情况1:如果 token 里确实包含 “bpm” 这个词,那就无条件相信这个数字。
情况2:如果 token 里没有 “bpm”(说明它就是个纯数字,比如 “120”),那就只在 60 到 200 这个“合理BPM范围”内才接受它。
if "bpm" in token.lower():
result["bpm"] = bpm_val
elif 60 <= bpm_val <= 200:
result["bpm"] = bpm_val
这个逻辑看上去,就比之前的那个“不看到bpm就不赋值”的逻辑靠谱多了吧?但如果有文件名叫"aaaaaa_120_121_122_123_Cmajor_one_shot”,那我要如何判断这个文件的BPM是多少?是120?121?
对此,如果你遇到了这样的文件,那我只想说LMA爱莫能助了。这是文件希望给你添麻烦,就算你不是个程序,你应该也不知道它到底在说什么。这也是我在用户说明文档里提到的“你需要手动修复”的原因。而对于一些文件,它万一在整活,它名字叫“采样_拍速一百二十_单采样”,那么你就算知道它BPM是120,由于命名是中文字符,也不在我设计的识别逻辑范围内。对此,LMA一样爱莫能助。
然后还有一个值得去提的是文件读取时闪退的解决方案。之前每次在尝试拖拽文件进Ableton或者桌面的时候,程序都会立即闪退。后来我推测可能是复制没完成,缓存里的内容就被立即清理掉了,导致任务进程断掉的同时,程序也不知道这个时候接下来应该做什么,于是就闪退了。所以我将临时文件的删除设置成了拖拽后5秒再删除,而如果删除失败,程序一样不会崩溃,而是会忽略掉这件事。
def cleanup_temp_file():
try:
if os.path.exists(temp_copy):
os.remove(temp_copy)
except Exception as e:
print(f"Info: Could not cleanup temp file (likely in use, this is OK): {e}")
QTimer.singleShot(5000, cleanup_temp_file)
虽然这个事情发生的概率并不大,毕竟音频文件这种一般不会到100mb的东西,5秒复制的时间在现代操作系统上是绰绰有余,但万一发生,临时文件就会变成一个垃圾被放在那里不管。我虽然不知道是否Windows/MacOS会在未来自行清理这种临时文件,但如果不会的话,那我未来就需要再开发一个自清理的逻辑,并且有自动化的触发条件去避免垃圾的堆积。
控制变量的排错同样也浪费了我大量的时间。在我加入了上述提到的这些drag & drop后,新的LMA版本在初始化后选择文件夹时,读取文件时会闪退。我一直以为是选择文件夹时读取需要时间,而我没有类似的逻辑给程序一些读取文件的时间所导致。但后来,我才发现是因为我没有把LMA拖入非开发电脑的Application文件夹。很多这样的问题的产生都非常的莫名其妙,其产生的可能多种多样。程度内的debug只能帮助你判断程序内运行失败的闪退,但这种程序在IDE里编译没问题,在开发设备上运行也没问题,一出开发设备就水土不服的情况实在是太让我头疼。
最后,不得不再提一下MacOS的开发者签名问题了。苹果的安全策略真令我感到有些不把用户当智力水平正常的人类了。
由于我直接打包的程序是“未经认证的”,所以在开发Mac上打包好的程序被发送到其它的Mac上,MacOS的安全机制“Gatekeeper”在一些情况下会使用比“拒绝访问”更严厉的一层“拒绝”,也就是直接告诉你“文件已损坏,你应该把它移动到垃圾桶”。在这种情况下,MacOS甚至不会在安全与隐私里允许你手动访问文件。
最初MacOS不停的显示文件已损坏但开发电脑上运行畅通无阻这点让我非常困惑,后来我发现是MacOS在对我说谎。说真的,我一开始也一度认为我打包时漏东西了,所以我根本就没往MacOS身上甩锅。后来我发现问题真不是我自己而是Gatekeeper的时候我真想让苹果把我浪费的debug时间全部给我还回来,我真不知道用什么语言才能形容我这种无力感。当我强制更新签名然后再一次把相同的文件发送到非开发的系统上时,LMA正常运行了。但这是我连着做了两次的操作,而且是我这个开发者就盯着两台电脑且知道问题出在哪时才会出现的情况。如果是我分发程序给用户,那用户看到了文件已损坏,他又会认为文件本身有问题。今天我就收到了一位朋友的反馈,所以对此我真的很无语。
当然,解决方法也存在。打开Terminal然后这么做:
xattr -cr <输入应用程序的位置,把程序拖进来也可以>
但毕竟我并非为拥有强计算机操作基础的人设计此软件,我的目标用户是所有人,所以我需要最小化他们的麻烦。这件事情依然是我需要避免的。
最终,我不得不进行类似主动申请权限(entitlements.plist)后手动覆盖旧的签名的操作,最后再打包成dmg文件让用户拖动到自己的Application文件夹,例如下列这样:
codesign --force --deep --sign - --options runtime --entitlements entitlements.plist "dist/SampleManager.app"
hdiutil create -volname "SampleManager" -srcfolder "dist/SampleManager.app" -ov -format UDZO "dist/SampleManager.dmg" #打包成dmg文件
新的dmg文件至少在非开发系统上能正常运行了。截止10.29日,我上传的用户端文件就是这个dmg。但即便是这样,我也不保证相同的问题不会发生,只能看更多人的反馈如何,我再做进一步的修正了。我成功打包成dmg并在我的另一台非开发的MacOS系统上运行了LMA后,由于我忘记了打包时exclude本地的那些json配置文件,我需要重新再打包一次。但这第二次打包又出现了问题。一次次排错实在是要把我的心态给整崩,我就只能把当前把测试用的文件也一起打包但测试无误的版本发送给大家测试了。如果要一劳永逸的去让自己开发的软件不被MacOS拦截,可能只有每年给苹果交年费吧(这性质和交保护费不一样吗,我真是良民啊大哥)。
当然,LMA会持续在未来不断的进步和自我迭代。我也会继续学习程序设计与开发相关的知识,争取更早更快的解决当前LMA上的bug。只是现在,有局限于个人的时间与开发水平,更新的速度应该会放缓一些。我会持续提升自己,争取未来能为LMA带来更多的功能,更快的读取与加载速度,更优秀的搜索逻辑,以及讲一些朋友为我提到过的功能加入进去,比如metadata文件的阅读,波形预览,更美观的图形操作界面等。
开发文档和我的吐槽会继续随着LMA的更新而更新。还有好多东西值得分享,也希望大家给我一些时间让LMA变得越来越好!